



Um sicher zu stellen, dass unsere Projekte solide und skalierbar sind und sich an zukünftige Änderungen anpassen können, ist die Anwendung einer guten Designarchitektur unerlässlich. Die hexagonale Architektur hilft uns, dieses Ziel zu erreichen.
Software-Architektur: Definition und Bedeutung
Im Bereich der Entwicklung sind wir mit immer komplexeren Systemen konfrontiert, die eine solide Struktur benötigen, um ihre Erstellung, Wartung und zukünftiges Wachstum zu erleichtern. Aus diesem Grund gewinnt der Begriff der Architektur im Bereich der Software zunehmend an Bedeutung.
Die Software-Architekturlegt eine Reihe von definierten und klaren Rahmenbedingungen für die Interaktion mit dem Quellcode fest und definiert auf abstrakte Weise die Menge der Komponenten, ihre Schnittstellen und die Kommunikation zwischen ihnen.
Diese Architektur wird auf Grundlage diverser Ziele erstellt, nicht nur funktionaler Art, sondern auch andere Ziele wie Wartung, Testbarkeit, Wiederverwendbarkeit, Flexibilität (in Bezug auf Änderungen) und Unabhängigkeit von anderen Systemen.
Beispiele für Architekturen sind: Model-View-Controller, Client-Server, Serviceorientiert (SOA), Ereignisgesteuert, Schichtenarchitektur oder hexagonale Architektur, um nur einige zu nennen.
Einführung in die hexagonale Architektur
ArchitekturIm Jahr 2005 veröffentlichte Alistair Cockburn einen Artikel[1], in dem er beschrieb, dass die Intention der hexagonalen Architektur darin bestand, dass eine Anwendung von Anwendern, Programmen, automatisierten Tests und Skripten auf die gleiche Art und Weise verwendet werden kann und dass sie sowohl isoliert von ihren eventuellen Geräten und Datenbanken während der Ausführung entwickelt und getestet werden kann.
Diese Architektur, auch Ports und Adapter-Architektur genannt, schlägt vor, unsere Anwendung in verschiedene Schichten oder Bereiche aufzuteilen, von denen jeder seine eigene Verantwortung hat, so dass sie sich isoliert entwickeln können und jeder von ihnen testbar und unabhängig von den anderen ist.
Um diese Schichtenunabhängigkeit zu erreichen, wird das Konzept von Ports und Adaptern verwendet. Ein Port ist nichts anderes als ein logisches Konzept, mit dem ein Ein- und Austrittspunkt der Anwendung definiert wird. Die Funktion des Adapters ist es, die Verbindung zu diesem Port und anderen externen Diensten zu implementieren. Auf diese Weise können wir mehrere Adapter für denselben Port haben. Zum Beispiel wird unser Framework einen SQL-Port für jede Anzahl von verschiedenen Datenbankservern anpassen, die unsere Anwendung verwenden kann.
Es gibt zwei Arten von Anschlüssen und Adaptern: primäre und sekundäre. Der Unterschied zwischen ihnen liegt darin, welcher die Kommunikation auslöst oder welcher dafür verantwortlich ist.
Im Fall von primären Ports und Adaptern ist es der Benutzer, der über die Benutzeroberfläche eine Anfrage an die Anwendung stellt. um Beispiel kann ein Benutzer über eine HTTP-Anfrage einen Eintrag anfordern. Diese Ports und Adapter sind auf der linken Seite des Hex-Diagramms zu sehen.
Bei sekundären Ports und Adaptern wird die Aktion dagegen von der Anwendung ausgelöst. Zum Beispiel könnte eine Datenbank-Persistenzanforderung aus einer Aktion eines primären Adapters erfolgen. Diese Fälle sind auf der rechten Seite des Hexagons dargestellt.
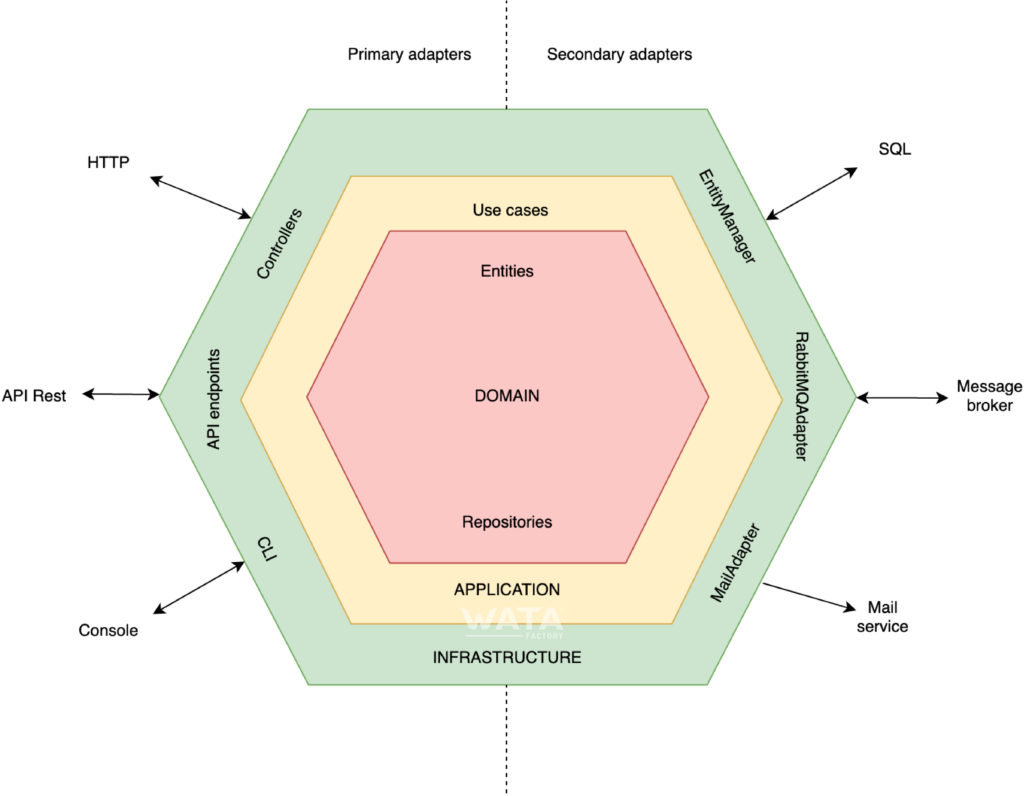
Die Form des Hexagons hat nichts mit der Anzahl der Seiten zu tun, sondern eher mit der Darstellungsform, da jede Seite einen Port darstellt, der entweder in die Anwendung hinein oder aus ihr heraus geht.
Schichtaufbau
Die hexagonale Architektur schlägt vor, die Anwendung in mehreren Schichten zu beschreiben. Der Grund hierfür ist, eine konzeptionelle Aufteilung der verschiedenen Bereiche der Anwendung zu erreichen. Der Code jeder Schicht würde beschreiben, wie man mit den anderen über Schnittstellen (Ports) und Implementierungen (Adapter) kommuniziert.
Auf diese Weise werden wir eine Anwendung haben, die wie folgt sein wird:
- Unabhängig von Frameworks: Das Projekt wird nie von einem externen Framework abhängig sein, da es immer eine Schicht geben wird, die die Logik abstrahiert und es ermöglicht, Frameworks zu wechseln, ohne die Anwendung zu beeinflussen.
- Testbar: Die Geschäftsprozesse können unabhängig von der Schnittstelle und externen Agenten getestet werden.
- UI-unabhängig: Das System ist nicht von der grafischen Oberfläche abhängig und diese kann geändert werden, ohne die Geschäftsprozesse der Anwendung zu beeinträchtigen.
- Datenbankunabhängig: Die Anwendungsdomäne weiß nicht, wie die Informationen strukturiert und in einem Repository gespeichert sind.
- Unabhängig von externen Agenten: Die Geschäftsprozesse haben keine Kenntnis von der Existenz eines externen Agenten. Sie müssen nur wissen, was diese Agenten zur Erfüllung ihrer Aufgaben benötigen.
Die Ebenen, in die wir unser System unter Anwendung dieser Architektur einteilen können, sind:
1. Die Domänenebene
Sie ist die zentrale Schicht des Hexagons und enthält die Geschäftsregeln. EDarin finden wir die Datenmodelle und deren Einschränkungen.
Diese Schicht weiß nicht, wie die Repository-Informationen strukturiert, gespeichert und abgerufen werden. Es wird einfach eine Reihe von Schnittstellen (Ports) exponiert, die in der Infrastrukturschicht für jeden spezifischen Fall der Implementierung dieser Persistenz angepasst werden.
2. Die Anwendungsschicht
Direkt über der Domänenschicht befindet sich die Anwendungsschicht, in der die verschiedenen Anwendungsfälle definiert sind. Bei der Definition der Anwendungsfälle denken wir an die Schnittstellen, die im Hexagon der Anwendung verfügbar sind, und nicht an eine der verfügbaren Technologien, die wir verwenden können.
In dieser Schicht werden auch die verschiedenen Anfragen, die die Anwendung von der Infrastrukturschicht erhält, angepasst. Ein Anwendungsfall akzeptiert beispielsweise Eingabedaten, die von der Infrastrukturebene kommen, und führt die notwendigen Aktionen aus, um Ausgabedaten an diese zurückzugeben.
3. Die Infrastruktur-Schicht
Dies ist die äußerste Schicht des Hexagons und entspricht den Implementierungen oder Anpassungen der Schnittstellen oder Ports der anderen Schichten.
Normalerweise entspricht diese Schicht dem Framework, aber sie enthält auch Bibliotheken von Drittanbietern, SDKs oder jeden anderen Code, der außerhalb der Anwendung liegt.
Die Infrastrukturschicht implementiert die in der Anwendungsschicht definierten Dienste (Sekundäradapter). Wenn wir darin zum Beispiel einen Dienst zum Senden von E-Mails oder SMS definiert haben, implementieren wir in dieser Schicht diesen Dienst entsprechend den Anforderungen des Providers oder einer externen Bibliothek.
Außerdem enthält diese Schicht alles, was mit der Interaktion mit dem Benutzer zu tun hat (Primäradapter). Sie erhält einige Eingabedaten, die zur Abfrage des entsprechenden Anwendungsfalls in der Anwendung verwendet werden, und gibt einige Ausgabedaten zurück. Hier finden sich u. a. HTTP-Treiber oder Kommandozeilenskripte.
4. Kommunikation zwischen den Schichten
Wie wir bereits erwähnt haben, muss jede Schicht eine Reihe von Ports definieren, die für jede konkrete Implementierung angepasst werden. Diese Ports sind die Klassenschnittstellen, die definieren, wie jede externe Schicht mit der aktuellen Schicht kommunizieren kann.
Um dies zu erreichen, verwenden wir Dependency Injection, d. h. wir injizieren die Abhängigkeiten in die Klasse, anstatt sie innerhalb der Klasse zu instanziieren. Auf diese Weise haben wir die Klassen der anderen Schichten entkoppelt, so dass sie von einer Schnittstelle abhängen, statt von einer konkreten Implementierung.
Was wir also erreichen, ist die Umkehrung der Steuerung der Anwendung, indem wir vermeiden, dass unser Programm von einer bestimmten Technologie abhängt, und es der Technologie ermöglichen, sich an die Anforderungen der Anwendung anzupassen.
Fazit
Bei WATA Factory haben wir dieses architektonische Konzept in einigen unserer größten Projekte verwendet. Es erlaubt uns, eine Isolierung jeder der Schichten zu erreichen, gibt uns Flexibilität, wenn wir eine Änderung der Infrastruktur oder eines externen Dienstes vornehmen, einfaches Testen und vor allem hilft es uns, SOLID anzuwenden, um mit der Zeit einen saubereren und besser wartbaren Code zu erhalten.


